





























In just over a week, the Linux ecosystem absorbed two of the worst local privilege escalation vulnerabilities in recent memory. Copy Fail dropped on April 29. Dirty Frag dropped on May 7 with a broken embargo and a working public exploit before any distribution had a patch ready.
xCloud shipped mitigation for both across more than 10,000 active customer servers on day zero, with no manual action, no SSH commands, and no immediate reboots required from customers.

This is what happened, what these vulnerabilities actually do, and how managed hosting infrastructure is supposed to respond when the kernel itself becomes the attack surface.
TL;DR: What xCloud Customers Need to Know
| Question | Answer |
| Are my xCloud servers patched for Copy Fail (CVE-2026-31431)? | Yes. Patched on May 1, 2026 — zero day. |
| Are my xCloud servers patched for Dirty Frag (CVE-2026-43284, CVE-2026-43500)? | Yes. Patched on May 8, 2026 — zero day. |
| Are my xCloud servers protected from Fragnesia (CVE-2026-46300)? | Yes. xCloud’s Dirty Frag mitigation already covered the same runtime exploit surface used by Fragnesia. |
| Did I need to take any action? | No. No SSH, no commands, no immediate reboots. |
| How can I verify the patch on my server? | Open xCloud panel → Server → Events → look for the security patch event. |
| Were any customer sites compromised? | xCloud has no indication of customer impact tied to these CVEs at the time of writing. Investigation continues as standard practice. |
| What about new servers I provision today? | Build scripts were updated immediately. New servers ship protected from the first worker run. |
The short answer: xCloud’s centralized security patch orchestration handled both vulnerabilities across the entire fleet without customer intervention. Read on for the full technical and operational story.
What Happened: Two Zero-Day Linux Kernel LPE Vulnerabilities in Just Over a Week
Two unrelated security researchers disclosed two related Linux kernel vulnerabilities within eight days of each other. Both target the same dangerous primitive — controlled writes into the kernel page cache, the in-memory copy of files that the operating system uses for performance.
According to Xint Code, who discovered Copy Fail, the bug allows an unprivileged local user to perform a deterministic 4-byte write into the page cache of any readable file on the system. The 732-byte proof-of-concept gets root on Ubuntu, Amazon Linux, Red Hat Enterprise Linux, and SUSE.
According to Microsoft Security Research, Copy Fail affects virtually all Linux distributions running kernels released from 2017 onward, including Ubuntu 24.04 LTS, Amazon Linux 2023, Red Hat Enterprise Linux, SUSE 16, Debian, Fedora, and Arch Linux. The CVSS score is 7.8 (High).
Then Dirty Frag arrived a week later, disclosed by independent researcher Hyunwoo Kim (@v4bel). Same vulnerability class, different kernel subsystems, and a rougher disclosure path because the embargo broke before patches were ready.
Copy Fail vs Dirty Frag vs Fragnesia: Side-by-Side Comparison
| Attribute | Copy Fail | Dirty Frag | Fragnesia |
|---|---|---|---|
| CVE | CVE-2026-31431 | CVE-2026-43284 / CVE-2026-43500 | CVE-2026-46300 |
| Public disclosure | April 29, 2026 | May 7, 2026 | May 13, 2026 |
| Discoverer | Xint Code | Hyunwoo Kim (@v4bel) | William Bowling (V12 security) |
| Vulnerable subsystem | algif_aead | esp4 / esp6 / rxrpc | XFRM ESP-in-TCP |
| Bug type | Page-cache write | Page-cache write | Page-cache corruption |
| Public PoC available | Yes | Yes | Yes |
| xCloud mitigation live | May 1, 2026 | May 8, 2026 | Already covered by Dirty Frag mitigation |
| Customer action needed | None | None | None |
Both bugs sit in the same family as Dirty Pipe (CVE-2022-0847) from 2022 — modify the page cache through a kernel path that should not allow writes, and any subsequent read sees the modified copy. The disk file is untouched. File hashes still match. The compromise lives in RAM until the page is evicted or the system is rebooted.
That is the kind of bug where “but the file integrity check passed” is an incomplete answer.
What Is Copy Fail (CVE-2026-31431)?
Copy Fail is a logic bug in the Linux kernel’s authencesn cryptographic template that ships with the algif_aead module — the AEAD socket interface of the kernel’s userspace crypto API.
According to Palo Alto Networks Unit 42, the flaw originates from a buggy in-place optimization introduced to the Linux kernel in 2017. The 2017 optimization caused the source and destination scatterlists to point to a combined buffer. Because of this, page cache pages from a splice() call were improperly chained directly into the writable destination scatterlist. During cryptographic operations, the authencesn algorithm uses the caller’s destination buffer as a scratch pad. It writes four controlled bytes past the legitimate output region, crossing a chained scatterlist boundary, and fails to restore them.
In plain English: an unprivileged user can trick the kernel’s crypto path into writing four chosen bytes into the in-memory copy of a privileged file. Public write-ups showed targeting /usr/bin/su, the setuid-root binary present on most Linux distributions. The disk file stays clean. The page cache gets contaminated. When the setuid binary executes next, the kernel serves the modified cached page. Attacker code runs as root.
Why Copy Fail Was a Big Deal
According to Bugcrowd, this is the kind of bug that, when it exists at all, tends to sell on the broker market for the price of a house. Crowdfense pays in the $10K–$7M range for a universal Linux LPE — and the top of that band is reserved for exactly this kind of reliable, deterministic, no-race-condition primitive that works across major distributions.
The standard runtime mitigation is to block the vulnerable module from loading:
echo “install algif_aead /bin/false” > /etc/modprobe.d/disable-algif.conf
rmmod algif_aead 2>/dev/null || true
Cloudflare’s response post is a good read on what a serious infrastructure response looks like — it’s not just “apply patch.” It is detection, exposure mapping, mitigation, rollout, verification, and finally kernel updates. xCloud followed the same operational shape.
What Is Dirty Frag (CVE-2026-43284 + CVE-2026-43500)?
Dirty Frag is what happens when the embargo system breaks down. It is a vulnerability chain that combines two separate page-cache write flaws to achieve root on essentially every major Linux distribution.
According to Hyunwoo Kim’s public write-up, Dirty Frag chains the xfrm-ESP Page-Cache Write vulnerability (CVE-2026-43284) and the RxRPC Page-Cache Write vulnerability (CVE-2026-43500). Kim discovered both. Both abuse the same pattern — the zero-copy send path where splice() plants a reference to a page cache page into the frag slot of a sender-side socket buffer, and the receiver-side kernel code then performs in-place crypto on top of that page.
The chain matters because each variant alone has gaps. The xfrm-ESP path requires the ability to create a user namespace, which Ubuntu blocks by default through AppArmor policy. The RxRPC path does not require namespace creation, but the rxrpc.ko module is not loaded on most distributions. Ubuntu, however, loads rxrpc.ko by default. According to The Hacker News, chaining the two variants makes the blind spots cover each other, allowing root privileges on every major distribution.
The Embargo Break
This is where Dirty Frag became unusually urgent.
According to AlmaLinux and the timeline in Kim’s GitHub repository, Kim submitted detailed exploit information to the linux-distros mailing list on May 7, 2026, with an embargo set for May 12. The agreement was the standard one — five days for distributions to backport patches before public disclosure. Roughly nine hours later, an unrelated third party published the ESP exploit publicly, breaking the embargo and forcing the security community into a faster timeline.
Patches were not ready. Most major distributions were still in testing. The PoC was already in the wild.
That is the situation xCloud was responding to on May 8.
What Is Fragnesia (CVE-2026-46300)?
Just days after Dirty Frag, another Linux kernel local privilege escalation vulnerability appeared in the same page-cache corruption family. The new issue is called Fragnesia, tracked as CVE-2026-46300, and disclosed by William Bowling of the V12 security team.
Like Dirty Frag, Fragnesia targets the Linux kernel’s XFRM / ESP networking path and abuses the same broad runtime surface involving esp4, esp6, and related kernel networking modules. A public proof-of-concept was published by V12 security.
Fragnesia is not the same bug as Dirty Frag. It is a separate Linux kernel vulnerability, but it belongs to the same class of page-cache corruption vulnerabilities that allow local privilege escalation from low-privileged code execution to root access.
According to CloudLinux and AlmaLinux advisories, systems already mitigated against Dirty Frag through module blocking and runtime restrictions are also protected against Fragnesia’s immediate exploit path until patched kernels are deployed.
That meant xCloud’s Dirty Frag mitigation already covered the immediate Fragnesia runtime mitigation path across the active fleet.
xCloud had already:
- Blocked future autoload of
esp4,esp6, andrxrpc - Unloaded those modules where present
- Applied namespace restrictions where available
- Verified mitigation at the runtime layer instead of trusting script execution alone
For xCloud-managed servers, no additional customer action was required. The runtime mitigation was already active while patched kernels continue rolling out through the normal controlled remediation path.
Affected Distributions
| Distribution | Affected? | Patched kernel status as of May 8 |
| Ubuntu 24.04.4 | Yes | Released for Copy Fail; Dirty Frag in testing |
| Red Hat Enterprise Linux | Yes | Copy Fail patched; Dirty Frag expedited per RHSB-2026-003 |
| AlmaLinux 8 / 9 / 10 | Yes (xfrm path); 9/10 only on RxRPC if kernel-modules-partner installed | Patches in testing |
| CentOS Stream 10 | Yes | Patches in testing |
| Fedora 44 | Yes | Patches in testing |
| openSUSE Tumbleweed | Yes | Patches in testing |
| Amazon Linux 2023 | Yes | Per AWS bulletin, affected versions being confirmed |
| CloudLinux 7h / 8 / 9 / 10 | Yes | KernelCare livepatches released for Copy Fail; Dirty Frag patches available |
Why These Vulnerabilities Matter for WordPress Hosting
A normal WordPress security incident does not start at the kernel. It usually starts at the application layer — a vulnerable plugin, a compromised theme, a leaked credential, an abandoned admin account, or a site owner installing something they should not have trusted.
That is already bad. A local privilege escalation on the host kernel makes it worse.
If an attacker gets low-privileged code execution through a WordPress site (the standard outcome of most plugin or theme compromises) and the host kernel is vulnerable to Copy Fail or Dirty Frag, the question becomes whether one compromised site can become root on the entire server. From there, the attacker can read other customers’ files, modify other sites on the same machine, plant persistence, and pivot.
That is the line good hosting architecture is supposed to defend.
The standard layered controls for managed WordPress hosting include:
- Site-level isolation so one hacked WordPress installation does not casually read or modify another
- Least-privilege execution boundaries
- Centralized patch orchestration
- Early external security signal
- Runtime mitigation
- Kernel patching and reboots as the final fix
Copy Fail and Dirty Frag specifically attack the layer below the application sandbox. They test whether your hosting platform has real isolation, whether your patching system can move at fleet speed, and whether your team responds to researcher signal without waiting for a perfect advisory.
How xCloud Responded: The Day-Zero Workflow
xCloud’s response to both vulnerabilities followed the same shape, with one key difference between Copy Fail and Dirty Frag.
The Worker-First Approach
xCloud manages servers through a centralized orchestration layer. Instead of asking customers to SSH into machines one by one, xCloud ships mitigation through the same operational path used for server lifecycle automation, provisioning, and security patching.
The exact rollout pattern was:
- Worker push for existing servers. A patching worker was deployed first to check every active server in the fleet. If a server was unpatched, the worker patched it on the spot. This also covered any server provisioned mid-rollout — the worker would catch it on its first run.
- Build script update for new servers. Immediately after the worker rollout, the patch was added to xCloud’s server build scripts. From that point on, every newly provisioned server is protected from the start of the build process. As soon as build progress begins, the server is already covered.
- Verification at the runtime layer. The mitigation script does not report success on task execution alone. It checks runtime state and fails the task if the vulnerable module remains loaded or if the protective configuration cannot be confirmed.
This last point matters more than it looks.
Why Runtime Verification Beats Script Success
In an emergency, it is tempting to measure success by task execution — did the script run, did the job finish, did the dashboard show green, did the config file get written. For kernel mitigations, that is not enough.
A mitigation script can exit with success while the exploit path is still open. Examples:
- The modprobe configuration file exists, but the vulnerable module was already loaded and never unloaded.
- modprobe -n shows future autoload is blocked, but current runtime state is unchanged.
- rmmod fails because the module is in use.
- The vulnerable feature is built into the kernel rather than loaded as a module.
- A namespace control sysctl is unavailable on that kernel and the script silently skips the check.
- AppArmor’s unprivileged namespace restriction exists but is not enabled.
- The script drops page caches and reports success, but the attacker can immediately exploit the host again.
The last one is especially dangerous. Cache dropping is cleanup, not mitigation:
sync
echo 3 > /proc/sys/vm/drop_caches
That can help clear clean page-cache contamination after a test run. It does not kill an already-spawned root shell. It does not repair files modified on disk. It does not remove persistence. It does not stop the exploit from running again if the vulnerable path remains open.
xCloud’s bar is higher: do not report “security patch completed” if the runtime exploit path is not actually closed.
xCloud Zero-Day Response Timeline
| Date | Event | xCloud action |
| April 29, 2026 | Copy Fail (CVE-2026-31431) publicly disclosed by Xint Code | Engineering triage begins |
| April 30, 2026 | Cloudflare publishes mitigation guidance; Ubuntu releases module-disable mitigation | xCloud builds patching worker |
| May 1, 2026 | xCloud rolls out Copy Fail mitigation across active fleet | Zero-day patched. Build scripts updated. |
| May 7, 2026 | Dirty Frag exploit published publicly after embargo break | Engineering triage begins immediately on early researcher signal |
| May 13, 2026 | Fragnesia / CVE-2026-46300 publicly disclosed with public PoC | xCloud confirms Dirty Frag mitigation already covers the immediate runtime mitigation path |
| May 8, 2026 | AlmaLinux, Red Hat, AWS, CloudLinux publish advisories | xCloud rolls out Dirty Frag mitigation across 10,000+ active servers. Zero-day patched. Build scripts updated. |
For Dirty Frag, the early signal mattered. Webnestify’s Simon reached out very early about the vulnerability activity, which compressed the engineering response window. xCloud’s team was triaging the disclosure and exploit path before the wider community had stabilized on a mitigation pattern.
What xCloud Patched: Specific Mitigation Steps
For technical readers, the mitigation set that went into the patching worker covered the following on each server:
For Copy Fail (CVE-2026-31431):
- Block future autoload of the algif_aead module
- Unload the module if currently loaded
- Verify the module is no longer present in lsmod
- Fail the task if either runtime state cannot be confirmed
For Dirty Frag (CVE-2026-43284 + CVE-2026-43500):
- Block future autoload of esp4, esp6, and rxrpc
- Unload those modules if currently loaded
- Disable unprivileged user namespaces where the kernel exposes the control
- Enable AppArmor’s unprivileged user namespace restriction where available
- Verify each control at the runtime layer
- Fail the task if any check cannot confirm the exploit path is closed
The same runtime mitigation path also covers Fragnesia / CVE-2026-46300 because the exploit targets the same broad XFRM / ESP attack surface. Since xCloud had already blocked and verified the relevant runtime modules during the Dirty Frag rollout, existing servers were already protected when Fragnesia was disclosed.
Verification was performed against runtime state, not configuration files. The worker queries /sys/module/<name> and parses lsmod output to confirm each targeted module is no longer present in kernel memory, rather than trusting that the modprobe blacklist file was written. The task fails loudly if either source disagrees with the expected state.
xCloud verified that algif_aead, esp4, esp6, and rxrpc are compiled as loadable modules on all fleet kernel builds. For kernel builds where a vulnerable feature is built into the kernel image rather than as a loadable module, the runtime mitigation path alone is insufficient and a reboot into a patched kernel is required as soon as available.
The mitigations follow the publicly documented pattern from CloudLinux’s Dirty Frag advisory and the AlmaLinux disclosure, with additional verification steps. Once distribution-level kernel patches and KernelCare livepatches roll out across affected base images, the long-term remediation path will be patched kernels and controlled reboots, treating runtime mitigation as the bridge.
A Note on IPsec and RxRPC Compatibility
For most managed WordPress hosting workloads, blacklisting esp4, esp6, and rxrpc has no practical impact. These modules are the kernel-side ESP transforms used by IPsec and the AF_RXRPC transport used almost exclusively by AFS clients — neither is part of a typical WordPress hosting stack. xCloud servers do not run IPsec tunnels for customer workloads, so the mitigation is operationally clean. Hosts that terminate or transit IPsec / strongSwan / Libreswan tunnels on shared infrastructure would need to evaluate the trade-off carefully — that is not the xCloud profile.
Site Isolation: The Layer Below the Kernel Patch
Kernel bugs are serious, and the right response is to patch fast. But kernel mitigation is not the only line of defense at xCloud, and that mattered during this incident.
In a managed WordPress hosting environment, the most likely initial foothold is still an application compromise. A bad plugin or theme should not give an attacker an easy path to other sites on the same server. xCloud’s isolation model is built around that assumption — sites are separated so one compromised WordPress installation cannot casually read or modify another.
That work is not glamorous. It is not a launch-day feature. It is the kind of engineering customers only notice when something goes wrong and the blast radius stays contained.
For Copy Fail and Dirty Frag, this prior investment mattered because the baseline posture was already stronger before the kernel mitigation rolled out. xCloud was not relying on kernel patching as the only line of defense. The layered controls in place during the incident:
- Site-level isolation
- Least-privilege execution boundaries
- Centralized patch orchestration ready to ship
- Early external security signal channels
- Runtime mitigation deployable in hours
- Kernel patching and controlled reboots as the final remediation path
That is the correct model for managed hosting. Not one magic wall. Multiple walls.
What xCloud Customers Need to Do
Nothing. That is the honest answer.
If a customer wants to confirm the mitigation completed on their server, the verification path is:
- Open the xCloud panel
- Navigate to the affected server
- Open Server → Events
- Look for the security patch event for Copy Fail (logged on or after May 1, 2026) and Dirty Frag (logged on or after May 8, 2026)
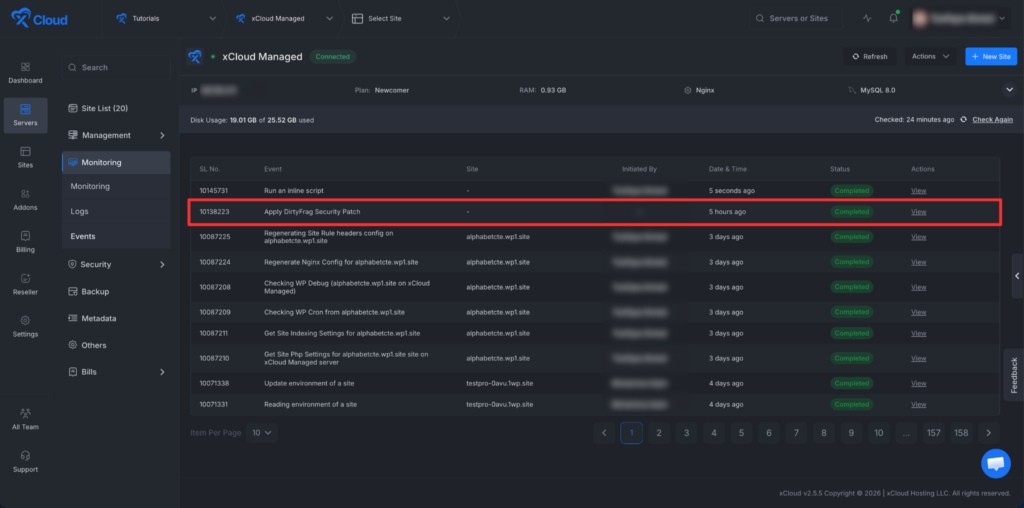
For self-managed Linux servers running outside xCloud, the standard incident response checklist applies:
- Track the distribution’s kernel advisories
- Apply patched kernels as soon as they are available
- Reboot into the patched kernel
- If patches are not available yet, apply runtime mitigations from trusted sources (Cloudflare, Red Hat, AlmaLinux, CloudLinux)
- Verify runtime state, not just script output
- If a public PoC was run on the server for testing, reboot the server afterward at minimum
- If exploitation is suspected, treat the server as compromised — dropping caches clears contaminated memory pages, but does not remove root shells, on-disk changes, or persistence installed after escalation
For xCloud-managed servers, the platform absorbs this operational burden by design. When urgent Linux security issues appear, xCloud moves through the orchestration layer instead of requiring manual server-by-server intervention from customers.
Behind the Scenes: How Day-Zero Mitigation Actually Works
The boring engineering systems matter most in moments like this. The day-zero rollout for Dirty Frag across 10,000+ active servers was possible because the underlying systems were already in place:
- Centralized server orchestration: Every xCloud server is reachable through the same operational path used for provisioning, configuration management, and routine maintenance. Patching workers ride that path.
- Patch workflow as a security capability: The patching system was not built for marketing copy. It was built so that when a real kernel vulnerability lands, the engineering team is not writing shell scripts in a Slack thread at midnight — the workflow exists, the rollout pattern is rehearsed, and the verification logic is already coded.
- Build pipeline integration: Adding a mitigation to the active fleet is half the job. The other half is making sure the next server provisioned does not arrive vulnerable. xCloud’s build scripts are updated in the same workflow as the active patch rollout, which closes the gap between “fleet patched” and “all future servers patched.”
- Verification, not just execution: Tasks fail if mitigation cannot be verified at the runtime layer. That is a small detail with a big impact. It is the difference between a green dashboard and an actually safe server.
- Researcher signal: Early external signal beats late official advisories. The Dirty Frag response benefited from early researcher contact through the security community before the wider disclosure stabilized.
This is what “managed hosting” should mean — not a control panel for buying servers, but an infrastructure platform that absorbs the operational burden of keeping those servers safe.
How xCloud’s Response Compared to the Industry
| Provider / Platform | Copy Fail mitigation timing | Dirty Frag mitigation timing | Customer action required |
| xCloud | May 1, 2026 (zero day) | May 8, 2026 (zero day) | None |
| Cloudflare (their own infrastructure) | Same-day mitigation across edge fleet | Not yet publicly documented at time of writing | None — internal infrastructure |
| Ubuntu (kmod mitigation) | April 30, 2026 | Patches in testing | Manual update + reboot |
| AlmaLinux | Patched kernels released | Patches in testing | Manual update + reboot |
| Red Hat (RHSB-2026-003) | Patched kernels released | Expedited patches | Manual update + reboot |
| CloudLinux KernelCare | Livepatch released | Livepatches in development | Automatic for KernelCare subscribers |
| Self-hosted servers (DIY) | Admin must patch | Admin must patch | Full manual response |
The xCloud profile here is straightforward — managed hosting is supposed to absorb the operational burden so customers do not have to chase advisories, write modprobe scripts, or schedule reboot windows during a kernel CVE storm.
Frequently Asked Questions About Copy Fail, Dirty Frag, and xCloud’s Response
What is Copy Fail (CVE-2026-31431)?
Copy Fail is a Linux kernel local privilege escalation vulnerability disclosed on April 29, 2026 by Xint Code. It is a logic flaw in the algif_aead kernel module that lets an unprivileged user perform a controlled 4-byte write into the page cache of any readable file on the system. The CVSS score is 7.8 (High). The vulnerability has affected all Linux kernels since 2017.
What is Dirty Frag?
Dirty Frag is a vulnerability chain disclosed on May 7, 2026 by researcher Hyunwoo Kim (@v4bel). It combines two flaws — CVE-2026-43284 in the IPsec ESP path and CVE-2026-43500 in the RxRPC path — into a reliable local privilege escalation that works on essentially every major Linux distribution. The xfrm component has been vulnerable since January 2017; the RxRPC component since June 2023.
Why is Dirty Frag described as “Copy Fail 2”?
Some community references and a proof-of-concept repository used the nickname “Copy Fail 2” for the xfrm-ESP variant. There is no separate CVE for “Copy Fail 2.” The vulnerability is officially Dirty Frag (CVE-2026-43284 + CVE-2026-43500). Copy Fail (CVE-2026-31431) is the original April 29 disclosure.
Are these vulnerabilities exploitable from the internet directly?
No. Both are local privilege escalation vulnerabilities. An attacker needs some form of code execution on the server first — typically through a compromised WordPress plugin, theme, application, or user account. The danger is that once they are in, these kernel bugs let them escalate from low-privileged code execution to full root.
Did xCloud servers get exploited by Copy Fail or Dirty Frag? X
Cloud has no indication of customer impact tied to these CVEs at the time of writing. Investigation continues as standard practice. Site-level isolation, mitigation rollout on day zero, and the absence of typical entry conditions (no shared IPsec terminations, restricted shell access on customer servers) all reduce exposure.
How can I verify the patch was applied to my xCloud server?
Open the xCloud panel, go to your server, and check Server → Events. Look for the security patch event logged on or after May 1, 2026 (Copy Fail) and on or after May 8, 2026 (Dirty Frag). No SSH access required.
Do I need to reboot my server?
Not immediately. The runtime mitigation protects your server now without requiring a reboot. xCloud will roll out patched kernels and schedule controlled reboots as the permanent fix — you’ll be notified in advance so you can plan around any brief maintenance window.
Will the mitigation break any of my WordPress sites or applications?
No. The blacklisted modules — algif_aead, esp4, esp6, rxrpc — are not used by typical WordPress hosting workloads. algif_aead provides a userspace interface to kernel crypto; well-behaved applications fall back to userspace crypto libraries automatically. esp4 and esp6 are IPsec ESP transforms, not used by standard web hosting. rxrpc is the AFS transport, not present in typical hosting stacks.
What happens to new servers I provision today?
They are protected from the start. xCloud’s build scripts were updated immediately after the active-fleet rollout. As soon as a build job starts, the server arrives with the mitigation in place. The patching worker would also catch any edge case where a server is provisioned mid-rollout.
What if I run my own Linux servers outside xCloud?
Track your distribution’s kernel advisories, apply patched kernels when available, and reboot. While waiting for patches, apply the module-blacklist mitigation from a trusted source — CloudLinux, AlmaLinux, Red Hat, or Cloudflare all have public guidance. Verify the mitigation at the runtime layer, not just by checking that the script returned success.
Why didn’t unattended-upgrades just handle this?
Unattended upgrades will eventually pick up patched kernels through normal distribution updates. The problem is timing. With Dirty Frag specifically, the embargo broke before patched kernels were ready, so there was a window where the public PoC existed but the fix did not. That is exactly the window where runtime mitigation matters. Waiting for the normal patch cycle would have left customer servers exposed during the highest-risk period.
What does this say about xCloud’s overall security posture?
It says xCloud treats infrastructure automation as a security capability, not just a convenience feature. Site isolation is in place. Patch orchestration works at fleet speed. Build scripts and active-fleet patches are updated together. Mitigations are verified at runtime instead of by script exit code. And when researcher signal arrives early, the engineering response is immediate. None of those things are accidents — they are years of boring infrastructure work that pays off exactly in moments like this.
Final Thoughts: What “Safe” Actually Means
Copy Fail, Dirty Frag, and Fragnesia are not just kernel vulnerability stories. They are architecture stories. They test whether a hosting platform has real isolation, whether the patching system can move at fleet speed, whether the team responds to researcher signal without waiting for a perfect advisory, and whether automation verifies reality or just paints the dashboard green.
When xCloud says customer infrastructure is safe, the claim is not that Linux kernel vulnerabilities are harmless. They are not. The claim is more specific:
- Site isolation reduces the chance that one compromised WordPress site becomes a broader server compromise
- The engineering team received early researcher signal and responded immediately
- The automation required to roll out mitigation across 10,000+ active servers existed before the incident, not after
- Mitigation was added to both existing-server patching and new-server provisioning paths in the same operational workflow
- Patched kernels and controlled reboots remain the final remediation path, not the only line of defense
- Confirmed malicious exploitation would be handled as a real security incident, not “fixed” by a cache drop
That distinction matters. Security is not pretending risk does not exist. Security is reducing risk quickly, verifying the controls, and being honest about what remains.
Linux kernel bugs will keep happening. The right response is not panic. It is preparation. xCloud has spent years building the boring systems that matter in moments like this — site isolation, server orchestration, patch workflows, provisioning automation, and security response loops. That work paid off when Copy Fail dropped on April 29, Dirty Frag dropped on May 7, and Fragnesia appeared days later with another public Linux kernel privilege escalation PoC.
The standard for managed WordPress hosting in 2026 is fast response, real isolation, verified mitigation, and no security theater. That is the standard xCloud is building toward, one zero-day at a time.



