
























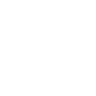





Gemma 4 is a lightweight open model family from Google that can be run through Ollama. It gives you a way to run OpenClaw with a local or self-hosted model setup using Ollama on xCloud. This is useful if you want more privacy, no API costs, and more control over how your model is hosted.
In xCloud, this setup lets you pair:
- OpenClaw for the AI agent runtime
- Ollama for local or self-hosted model serving
- Gemma 4 as one of the available models for your agent workflows
Gemma 4 is a recently introduced model that you can try alongside other options such as DeepSeek R1 and more. This setup works well if you want to experiment with private or lower-cost agent workflows on xCloud.
Follow this guide to run Gemma 4 with Ollama and connect it to OpenClaw on xCloud.
Step 1: Deploy OpenClaw on xCloud #
If you have not already deployed OpenClaw, follow the xCloud OpenClaw deployment guide.
In short, you need to:
- Create an xCloud Managed Server for OpenClaw
- Complete the initial provider or messaging setup
- Finish provisioning and confirm the OpenClaw instance is working
👉Read this documentation for a step-by-step guide to installing OpenClaw.
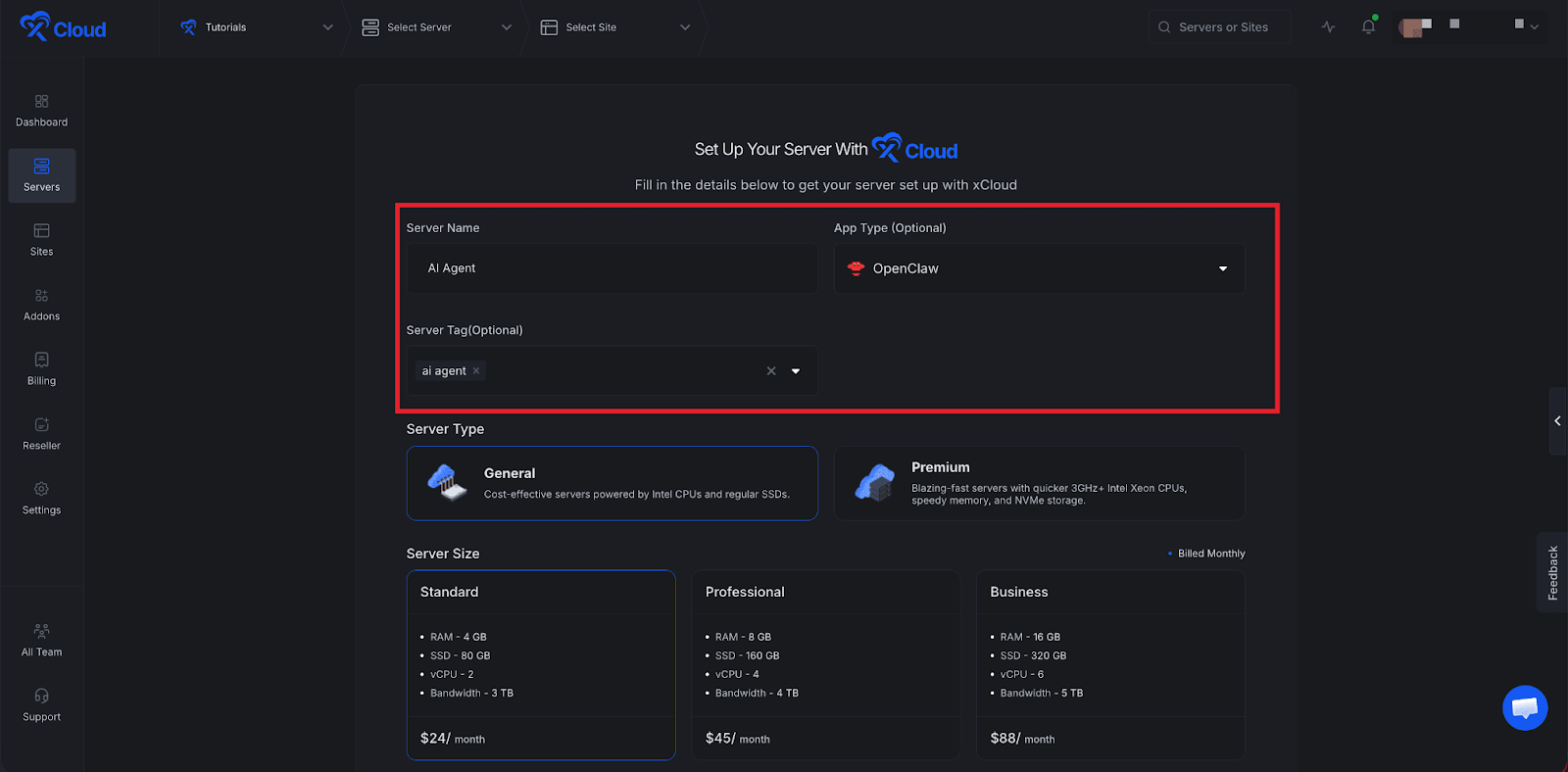
Step 2: Deploy Ollama on xCloud #
Next, deploy Ollama using xCloud’s self-hosted LLM workflow. You can install Ollama on a Docker NGINX server.
If you are using xCloud’s Ollama app flow, complete the installation and confirm the service is running before connecting it to OpenClaw.
👉Read this documentation for a step-by-step guide to installing Ollama.
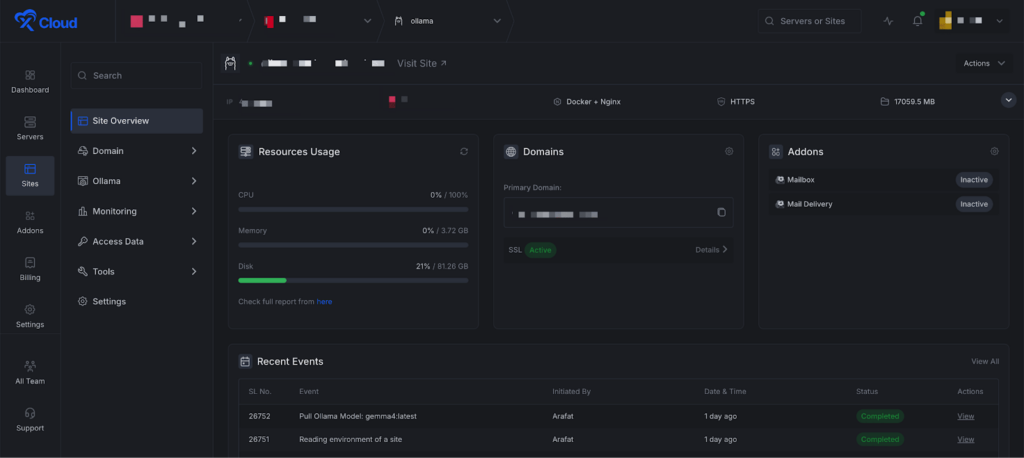
Step 3: Add a New Model #
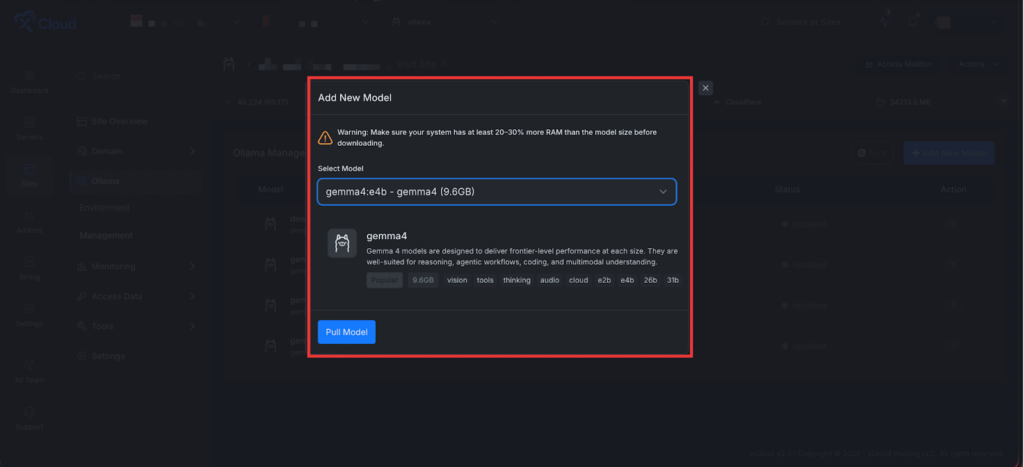
Next, go to ‘Ollama’ → ‘Management’ from your xCloud Ollama dashboard. Then, find the ‘Add New Model’ button and click on it.
A pop-up will appear. Select the ‘Gemma 4’ model from the dropdown and click on the ‘Pull Model’ button. It will start installing the Gemma 4 model in Ollama.
Step 7: Expose Ollama API (Important) #
- Open your Ollama server.
- Navigate to the Nginx config directory:
/etc/nginx/sites-available - Edit the config to expose the Ollama API endpoint.
- Save changes.
- Restart or reload Nginx.
- Verify the endpoint is accessible from OpenClaw.
Step 4: Open the OpenClaw Dashboard #
Next, go to your xCloud OpenClaw dashboard and click on the “Config” option from the sidebar.
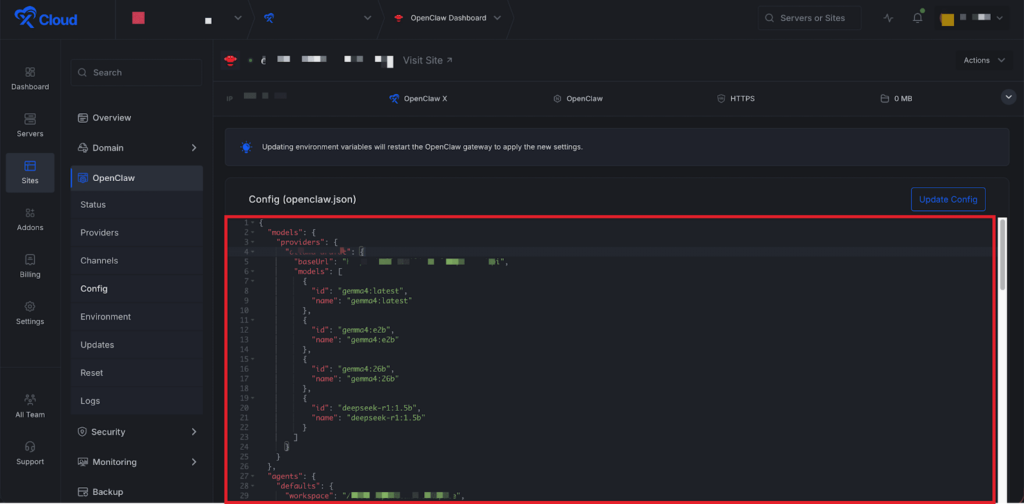
Step 2: Add an Ollama Provider #
Next, add your Ollama endpoint under the Model Provider section in your config file. You can also use the OpenClaw UI to update the config. Manual updates can lead to mismatches or incorrect setups.
Instead, use the OpenClaw UI chat or a messaging platform like Telegram. Share the config and details while chatting with your agent, and OpenClaw will automatically configure the provider for you.
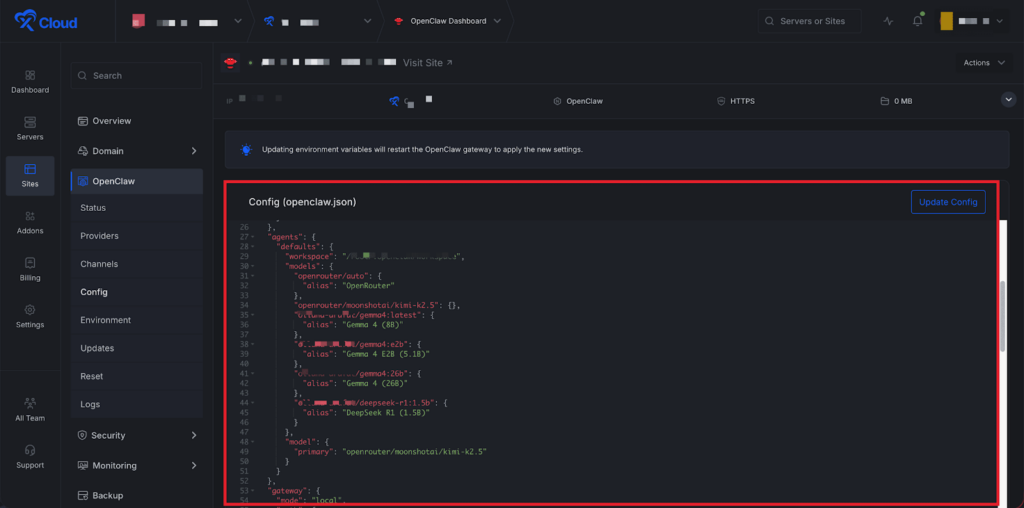
Step 3: Add the Models to Agent Defaults #
Scroll down in the config file and register those models in the default agent model list. After adding them, click the “Update Config” button to proceed.
💡 The format is: <provider>/<model> and alias is the display name shown inside OpenClaw.
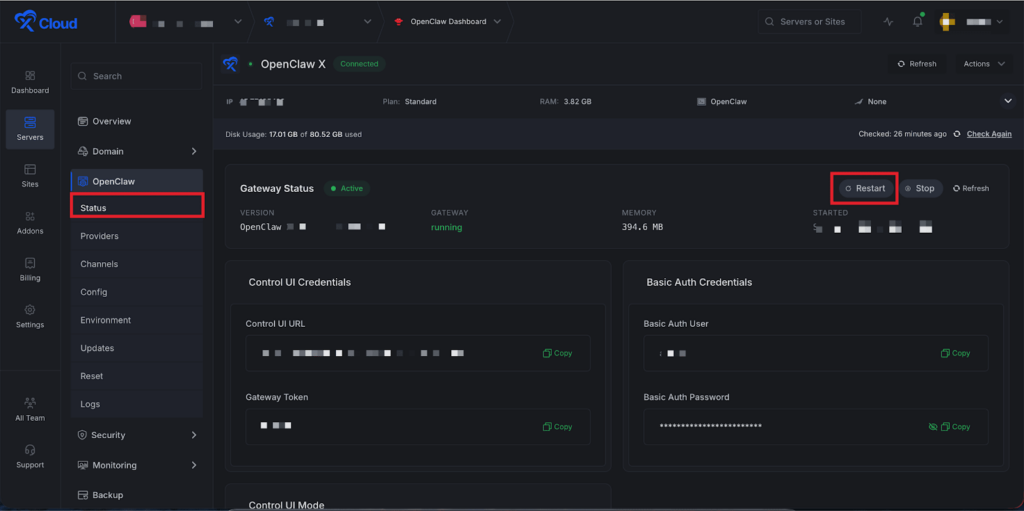
Step 4: Restart OpenClaw #
After saving the config, go to the “Status” option from the left-side menu in xCloud OpenClaw, then click the “Restart” button.
And that’s it, this is how easily you can run OpenClaw using Gemma 4 and Ollama in xCloud.
⚠️ Important: Expose Ollama API #
One important step to note is that your Ollama API must be accessible from your OpenClaw server. By default, the Ollama API may not be publicly reachable. Without exposing it, OpenClaw cannot communicate with your model.
To fix this, you need to update the Nginx configuration of your Ollama server and expose the API endpoint.
After updating the configuration:
- Reload or restart Nginx
- Verify that the Ollama endpoint is accessible from your OpenClaw server
Once the API is properly exposed, OpenClaw will be able to connect and use your Ollama models without issues.
That’s the full setup. You now have Gemma 4 running through Ollama and connected to OpenClaw on xCloud – a fully self-hosted agent stack with no external API dependencies.
If you run into issues, check that Ollama is running and accessible from your OpenClaw server, and make sure your model IDs in the provider config match exactly what Ollama reports.
Still stuck? Feel free to reach out to our support team.



